
最代码官方
2018-03-21 11:34:44
java脚本批量转换java utf-8 bom源码文件为utf-8编码文件
今天在最代码下载的一个项目基于ssm+easyui开发的公司员工后台管理系统,导入IntelliJ IDEA并且设置为java web项目后,编译的时候发现提示错误
Error:(1, 1) java: 非法字符: \65279
Error:(1, 10) java: 需要class, interface或enum

于是搜索一番发现是因为该java源文件编码是utf-8 bom文件,需要设置为utf-8 无bom文件,于是通过notepad++替换了2个java源码文件
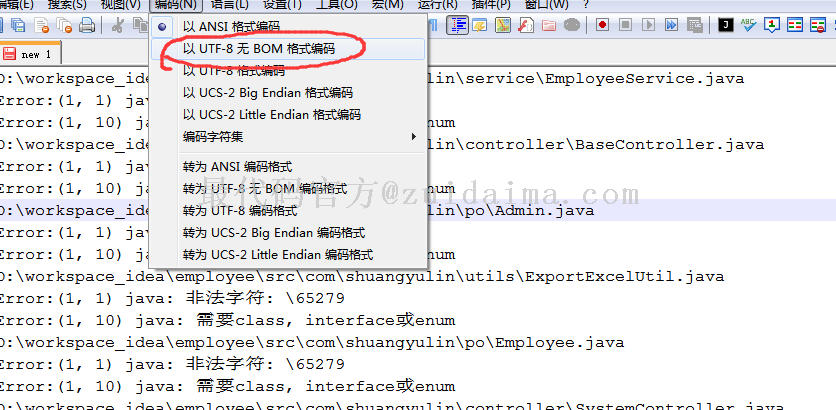
但是发现有几十个java源码文件,这样一个个替换确实太费劲了,于是想到批量转换,暂时没发现notepad++有此类插件,百度上发现editplus可以实现,可以参考https://jingyan.baidu.com/article/dca1fa6f4cea7cf1a5405210.html,另外发现通过java语言也可以实现该功能,代码如下
package com.javaniu.core.util;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* - changed BOM recognition ordering (longer boms first)
* 网络地址:http://koti.mbnet.fi/akini/java/unicodereader/UnicodeReader.java.txt
* Original pseudocode : Thomas Weidenfeller
* Implementation tweaked: Aki Nieminen
* http://www.unicode.org/unicode/faq/utf_bom.html
* BOMs:
* 00 00 FE FF = UTF-32, big-endian
* FF FE 00 00 = UTF-32, little-endian
* EF BB BF = UTF-8,
* FE FF = UTF-16, big-endian
* FF FE = UTF-16, little-endian
* Win2k Notepad:
* Unicode format = UTF-16LE
***/
/**
* Generic unicode textreader, which will use BOM mark
* to identify the encoding to be used. If BOM is not found
* then use a given default or system encoding.
*/
public class UTF8BOMConverter extends Reader {
PushbackInputStream internalIn;
InputStreamReader internalIn2 = null;
String defaultEnc;
private static final int BOM_SIZE = 4;
/**
* @param in inputstream to be read
* @param defaultEnc default encoding if stream does not have
* BOM marker. Give NULL to use system-level default.
*/
UTF8BOMConverter(InputStream in, String defaultEnc) {
internalIn = new PushbackInputStream(in, BOM_SIZE);
this.defaultEnc = defaultEnc;
}
public String getDefaultEncoding() {
return defaultEnc;
}
/**
* Get stream encoding or NULL if stream is uninitialized.
* Call init() or read() method to initialize it.
*/
public String getEncoding() {
if (internalIn2 == null) return null;
return internalIn2.getEncoding();
}
/**
* Read-ahead four bytes and check for BOM marks. Extra bytes are
* unread back to the stream, only BOM bytes are skipped.
*/
protected void init() throws IOException {
if (internalIn2 != null) return;
String encoding;
byte bom[] = new byte[BOM_SIZE];
int n, unread;
n = internalIn.read(bom, 0, bom.length);
if ((bom[0] == (byte) 0x00) && (bom[1] == (byte) 0x00) &&
(bom[2] == (byte) 0xFE) && (bom[3] == (byte) 0xFF)) {
encoding = "UTF-32BE";
unread = n - 4;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE) &&
(bom[2] == (byte) 0x00) && (bom[3] == (byte) 0x00)) {
encoding = "UTF-32LE";
unread = n - 4;
} else if ((bom[0] == (byte) 0xEF) && (bom[1] == (byte) 0xBB) &&
(bom[2] == (byte) 0xBF)) {
encoding = "UTF-8";
unread = n - 3;
} else if ((bom[0] == (byte) 0xFE) && (bom[1] == (byte) 0xFF)) {
encoding = "UTF-16BE";
unread = n - 2;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE)) {
encoding = "UTF-16LE";
unread = n - 2;
} else {
// Unicode BOM mark not found, unread all bytes
encoding = defaultEnc;
unread = n;
}
//System.out.println("read=" + n + ", unread=" + unread);
if (unread > 0) internalIn.unread(bom, (n - unread), unread);
// Use given encoding
if (encoding == null) {
internalIn2 = new InputStreamReader(internalIn);
} else {
internalIn2 = new InputStreamReader(internalIn, encoding);
}
}
public void close() throws IOException {
init();
internalIn2.close();
}
public int read(char[] cbuf, int off, int len) throws IOException {
init();
return internalIn2.read(cbuf, off, len);
}
private static void readContentAndSaveWithEncoding(String filePath, String readEncoding, String saveEncoding) throws Exception {
saveContent(filePath, readContent(filePath, readEncoding), saveEncoding);
}
private static void saveContent(String filePath, String content, String encoding) throws Exception {
FileOutputStream fos = new FileOutputStream(filePath);
OutputStreamWriter w = new OutputStreamWriter(fos, encoding);
w.write(content);
w.flush();
}
private static String readContent(String filePath, String encoding) throws Exception {
FileInputStream file = new FileInputStream(new File(filePath));
BufferedReader br = new BufferedReader(new UTF8BOMConverter(file, encoding));
String line = null;
String fileContent = "";
while ((line = br.readLine()) != null) {
fileContent = fileContent + line;
fileContent += "\r\n";
}
return fileContent;
}
private static List<String> getPerlineFileName(String filePath) throws Exception {
FileInputStream file = new FileInputStream(new File(filePath));
BufferedReader br = new BufferedReader(new InputStreamReader(file, "UTF-8"));
String line = null;
List<String> list = new ArrayList<String>();
while ((line = br.readLine()) != null) {
list.add(line);
}
return list;
}
private static List<String> getAllFilePaths(File filePath, List<String> filePaths) {
File[] files = filePath.listFiles();
if (files == null) {
return filePaths;
}
for (File f : files) {
if (f.isDirectory()) {
filePaths.add(f.getPath());
getAllFilePaths(f, filePaths);
} else {
filePaths.add(f.getPath());
}
}
return filePaths;
}
public static void main(String[] args) throws Exception {
String suffix = ".java";
List<String> paths = new ArrayList<String>();
paths = getAllFilePaths(new File("D:/zuidaima_idea/employee/"), paths);
List<String> pathList = new ArrayList<String>();
for (String path : paths) {
if (path.endsWith(suffix)) {
pathList.add(path);
}
}
for (String path : pathList) {
//注意如果是GBK编码的文件,需要2个参数为GBK,否则文件会乱码无法恢复
readContentAndSaveWithEncoding(path, "UTF-8", "UTF-8");
System.out.println(path + "转换成功");
}
}
}
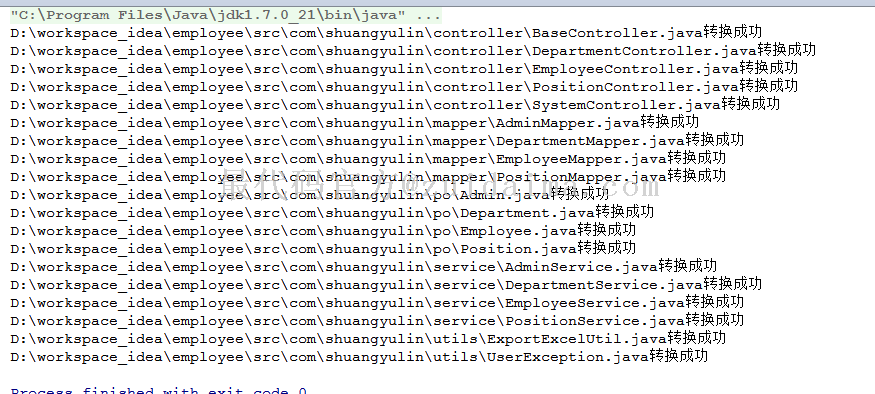
可以指定文件夹和后缀,这样程序就可以批量查找到某个文件夹下某种后缀的文件进行编码转换了,执行结果如下图
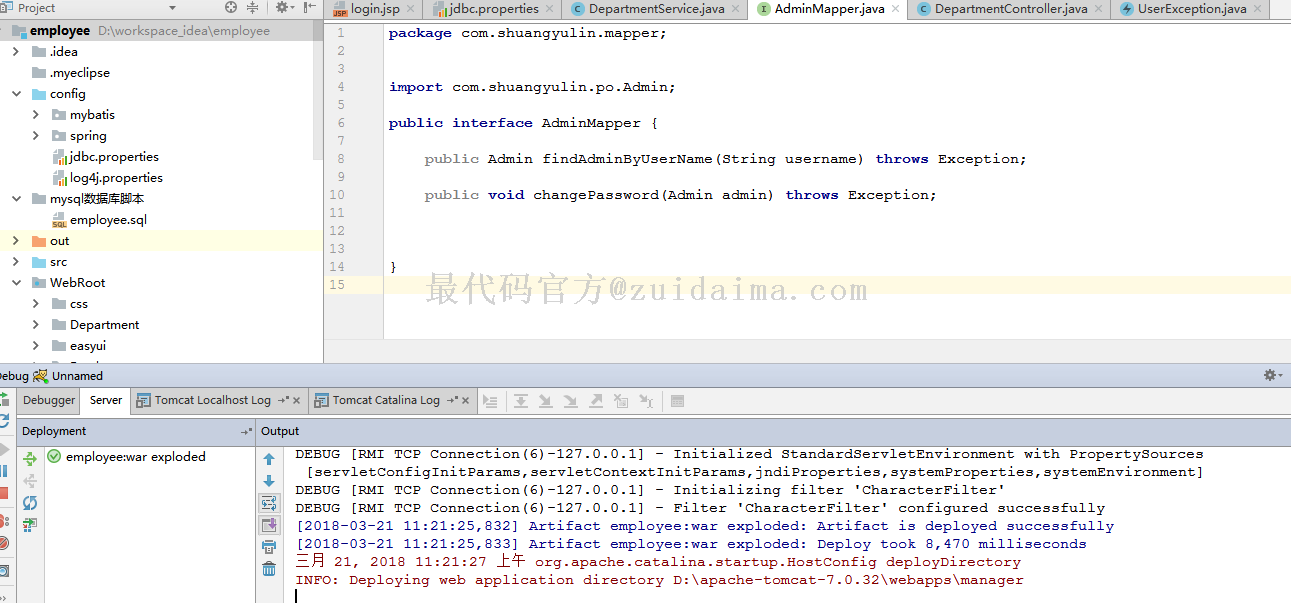
该项目已经可以在idea下正常编译和运行了
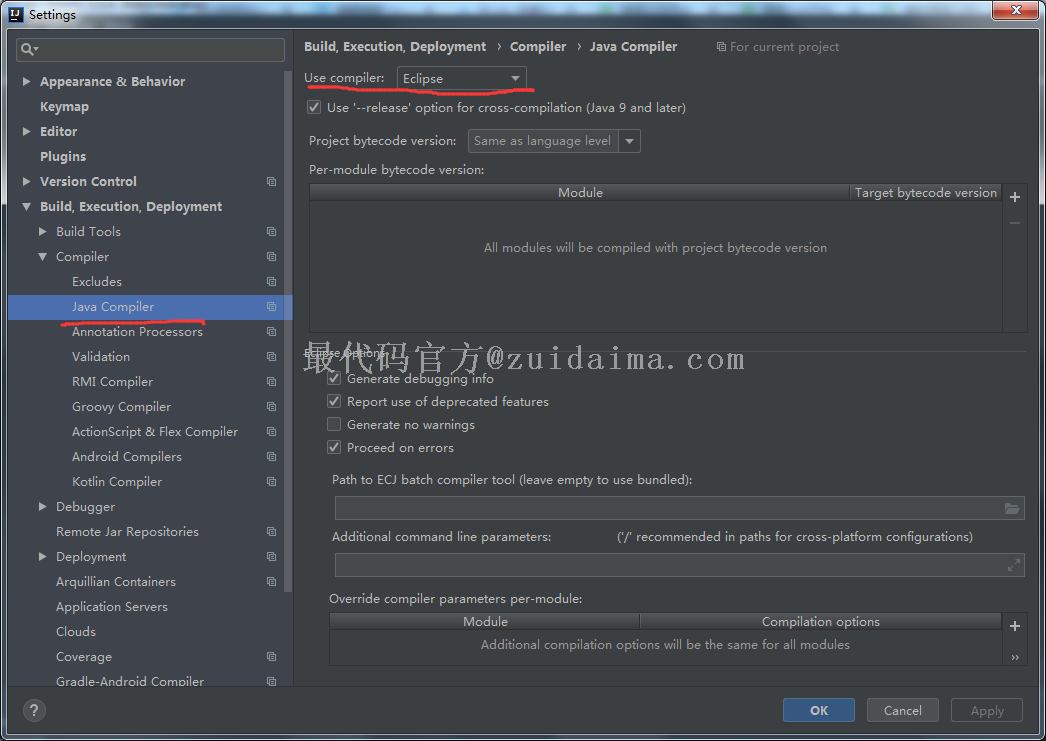
也可以通过设置Java Compiler为Eclipse来解决
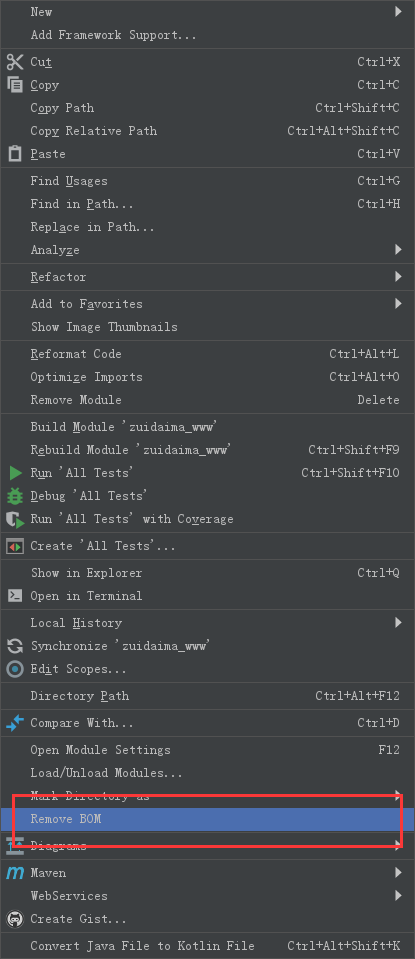
新版本idea在项目上点击右键有Remove BOM的菜单,点击也可以实现删除bom符号的目的
已有1人打赏

 最近浏览
最近浏览
wwy000 LV2
昨天

a2418735612 LV1
2024年1月4日
1762806977 LV4
2023年3月17日

微信网友_6350556908965888 LV1
2023年2月15日
微信网友_6281422282149888 LV2
2022年12月28日
2017143155 LV12
2022年12月2日
如果white LV2
2022年11月28日
niceeeee LV3
2022年11月23日
ijggggg LV1
2022年5月22日
xwmxwm LV4
2022年4月17日
