
这是一个发生在稳定性测试环境上的bug,简单描述下项目的架构:
项目的结构可分为四个部分,web端、数据中心、监控节点、ping节点。web端和具体的业务分开,只负责展示(tomcat进程),数据中心负责任务下发和数据回写的解析、分析以及入库(java进程),监控节点接收数据中心下发的任务,负责采集需要监控的设备的数据并解析组装然后发送给数据中心进行数据保存(java进程);ping节点接收数据中心下发的ping任务,负责可用性检测(当然现在很多企业对设备都是禁ping的,这种检测机制我们后面在做改变)(java进程);这几个服务间通过zeromq的push/pull方式进行通信。
从上面简单的描述可以看出,监控节点和ping节点是可以多机分布式部署的,也可以单机多进程部署
问题:
在测试环境跑了一段时间后,突然出现设备全面宕机的问题,但是实际情况是这是一次假宕机,设备真实的状态是正常的,从监控节点的日志中可以看出任务一直是按照给定的频率在执行。
这大概能够判断是ping节点的问题,因为设备的可用性状态是根据ping结果去判断的,于是拿出ping节点的日志来看,发现执行了一段时间后,报错如下:
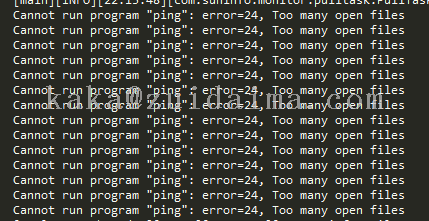
too many open files,除了这个异常其他任何异常都没有,简单解释下这个报错,在linux环境下,任何事物都是以文件的形式存在,我们模拟一条ping命令都是会打开一个文件句柄,造成这个问题的原因是linux中的文件句柄数已经达到了设置的最高值,所以后面再来ping任务,都不会去执行了,结果我们的系统默认就是宕机状态了。
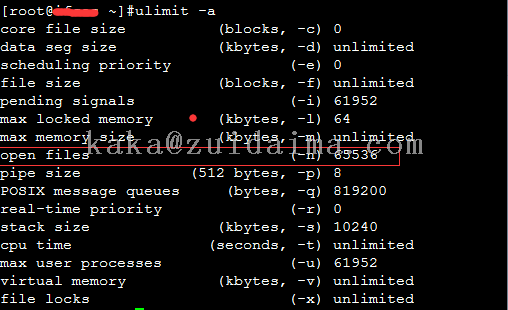
找到了产生这个异常的原因后,我查了下我们系统设置的最大文件句柄数 ulimit -n,果真是默认值1024

将最大文件数修改为65536,查看,ulimit -a
至此,我简单的以为这个问题就解决了,可是过了大概一周,这种情况又出现了....
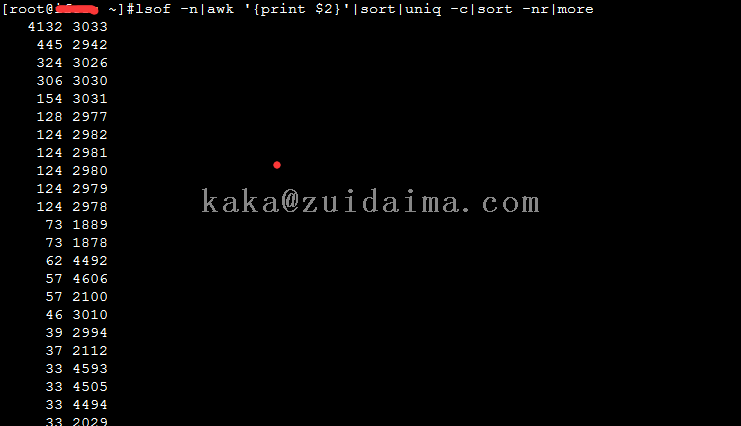
执行命令:lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|more,第一个是句柄数,第二个进程ID,3033是ping节点的进程ID,ping的句柄数为4132,但是也没达到最大数的限制,不知道为什么不能创建模拟的ping命令,但是可以肯定的是,肯定是项目中某处导致系统的文件数持续增长。
然后我开始翻阅我们ping这块的代码,所有调用结束后都释放了啊
但是我发现每一次ping执行,都会调用两次模拟ping命令,第一次是去拿ping标识(ping通还是ping不通),第二次是拿额外的一些信息,比如响应时间啥的,这块问了相关开发人员后确定是没必要进行两次操作的,只需要一次就可以搞定。调用代码如下:

上面这两行代码都会调用下面的这行代码

修改为一次后,每一个监控周期,产生的文件数会减少一半,但这肯定不是导致ping节点文件句柄数不断增大的原因,然后猜想应该是项目中存在很多流没有关闭导致的,翻看节点日志也看到了每隔三分钟(三分钟是我们的调度频率),都会打印加载监控模板文件(监控模板配置成xml形式,是监控依据的最基础的数据),这个不对啊,我们虽然部署的多个服务,但是使用的是memcached的分布式缓存,按道理应该加载一次的,后面都会从缓存中获取,然后看了下spring的配置文件,发现监控节点没有引入memcached.xml的配置文件,所以导致每一次监控都要加载全部的监控模板,而且之前读取这些xml都没有进行流关闭,我自己分析了下:我们的监控周期是3分钟,每三分钟监控节点都会去加载一遍所有的监控模板,并且流没有关闭,导致文件句柄数不断增加,其实并不是ping节点的问题,而是监控节点的问题。
在项目中找那些文件流没有关闭,还真找到了很多地方,一通修改后,修改后信心满满的部署上去,过了9天,这个问题又复现了。
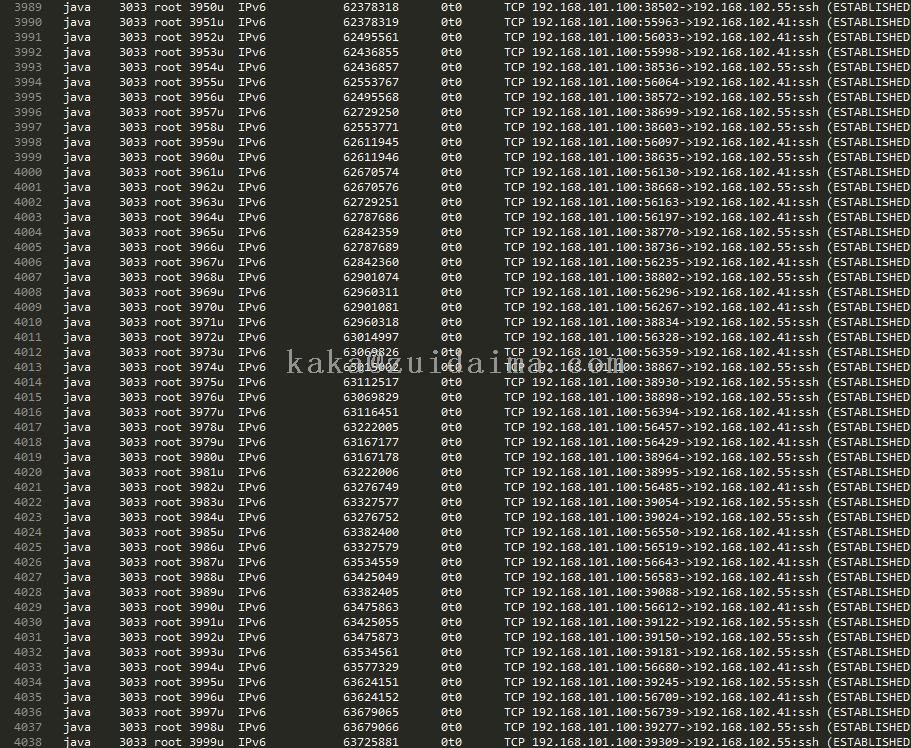
再去仔仔细细的翻看了了一遍ping节点的代码,发现有这么一个业务,每次ping的时候,还会有一个获取系统时间的操作,windows设备会用snmp或者wmi协议去获取,linux设备用ssh或者telnet去获取,嗯,这些设备获取系统时间后所有的链接都没有释放,这会我大概有70%的把握是这块导致的,我去测试环境上执行如下命令:lsof -p ping节点的进程ID,这个命令是查看进程里具体的打开句柄的东东,如下图,发现满屏都是创建ssh链接打开的文件句柄,至此就可以解释清楚了,我们测试环境只监控了24台设备,Linux和Solaris(配置了ssh凭证)加起来大概15台左右,ping节点每隔6分钟对这15台设备进行ping操作,一个监控周期就会打开15个文件句柄,一天就会打开15*10*24 = 3600,我们设置的最大句柄数是65536,大概能支撑的天数也就是65536/3600,大概18天左右,当然系统中不可能只有ping去打开文件句柄数,还有很多服务,也能解释的通ping节点运行9天后出现这个问题。
lsof -p 3033
将ping节点获取系统时间的链接关闭后,重新部署项目,再也没有出现假宕机的问题,虽然该问题解决了,但还是有如下疑虑:
1.从ping节点打开的文件句柄来看,只有45和51两台机器,且均是Solaris,其他的linux设备每次获取系统时间创建的链接也是没有关闭的,不清楚是不是有的linux设备有保护机制,长时间的ssh链接会被关闭掉?
2.进程和进程间是否不存在影响?每个进程系统是否都会分配一定量的文件数来保证某个进程导致文件句柄数增大而不影响其他进程的运行?从测试环境的情况看来,monitor节点每隔三分钟执行一次调度一直都是正常的,监控节点生成的ssh链接在结束后都会释放掉的。如果两个进程间的文件数没有限制,不可能只有ping节点出问题,监控数据也应该中断才对
通过这次排查,也能看出平时养成一种良好的编码习惯有多重要,每一行简单的代码,不留心也许会给系统带来意想不到的后果。

 最近浏览
最近浏览



