java servlet开发百度网盘搜索引擎盘一下网站源码分享
【写在前面】
在博客里面《我的站长之路》里面提到了一个百度网盘搜索引擎网站,今天晚上下班早还是决定回来分享一下源码吧!
【网站概况】
名字:盘一下 - 百度网盘搜索引擎
选用域名:www.panyixia.cn [ 有需要域名的牛牛 可以考虑这个域名 我打算转让 3年的 一口价在阿里云哦 ]
是否上线:否
【选用技术】
Jsp , Servlet ...
【网站截图】
网站首页

搜索结果页

其他页面(用QQ还真可以扫描加到我的哦!!!)
基本的情况就介绍的差不多了,由上面可以得知,网站技术很简单,所以不用担心你下载后你看不懂我的代码,接下来看看项目的整体一览图:
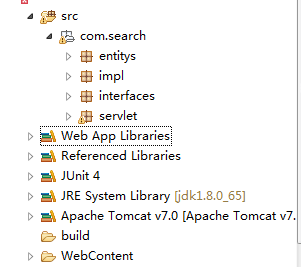
注意了,没有用maven哦,部分牛牛不会用maven,这个项目就不用担心跑不起来了,直接下载,丢进你的eclipse里面即可,看清楚了是eclipse哦
开发环境
win7 + eclipse + jdk1.8 + tomcat7
如果你不是和我一样的开发环境,又不会解决这些环境问题,我建议你不要下载我的代码,因为我可能没那么多时间给你解答环境对应的问题,见谅了!
为什么要这么说呢,因为在我之前的分享里面,部分人因为环境问题跑不起来,然后说我的代码不可用,实际上是因为环境问题导致的!所以,在这里特此说明一下。
简要的画了一个原理图,如下
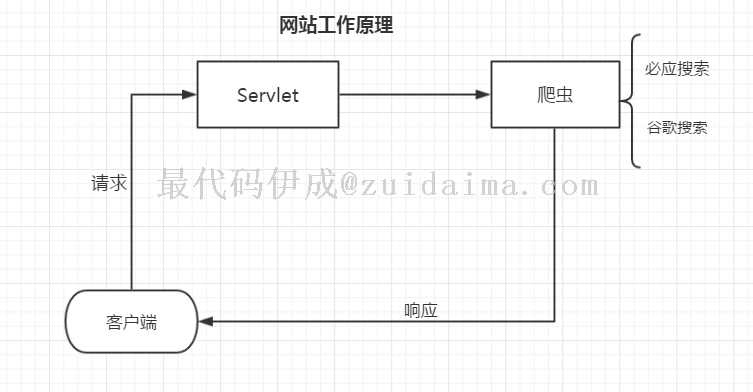
现在网盘搜索引擎,部分是接入第三方的接口(付费),部分则是自己开发。
代码里面其实用了两种方式
1.利用谷歌API
需要解决的问题只有两个。
①、谷歌自定义搜索接口。
②、如何访问谷歌接口。
以上是一种思路,但是天朝已经上不了谷歌了,但是有人还是要研究这种思路的,请自己去查找对应资料 搜索key给你了 --> Google自定义搜索
代码片段:
String urlStr="https://www.googleapis.com/customsearch/v1element?key=AIzaSyCVAXiUzRYsML1Pv6RwSG1gunmMikTzQqY&rsz=filtered_cse&num=10&hl=en&prettyPrint=false&source=gcsc&gss=.com&sig=8bdfc79787aa2b2b1ac464140255872c&start="+first+"&cx=014027524001724272181:fosdjczvtqc&q="+key+"&sort=&googlehost=www.google.com";
URL url = new URL(urlStr);
logger.info("---------------"+urlStr);
BufferedReader bufr = new BufferedReader(new InputStreamReader(new BufferedInputStream(url.openStream()),"utf-8"));
String line;
StringBuffer sb=new StringBuffer();
while((line = bufr.readLine())!=null){
sb.append(line);
}
bufr.close();
JSONObject jsonObject=JSONObject.fromObject(sb.toString());
JSONArray results=jsonObject.getJSONArray("results");
JSONArray r=new JSONArray();
List<Message> list = new ArrayList<Message>();
Message msg = null;
for(int i=0;i<results.size();i++){
JSONObject j=(JSONObject) results.get(i);
msg = new Message();
msg.setTitle(j.get("title").toString());
msg.setUrl(j.get("unescapedUrl").toString());
msg.setContent(j.get("content").toString());
list.add(msg);
}
2.利用别的搜索引擎(必应搜索引擎)
大体的思路其实都是一样的,只是换了一个壳子而已。
代码片段:
protected String crawlSource(String url) throws ClientProtocolException,
IOException {
CloseableHttpClient httpClient = HttpClientBuilder.create().build();
CloseableHttpResponse httpResponse = httpClient.execute(new HttpGet(url));
String result = EntityUtils.toString(httpResponse.getEntity());
return result;
}
@Override
public List<Message> getList(String url) {
String result = null;
List<Message> list = new ArrayList<Message>();
Message msg = null;
try {
result = crawlSource(url);
Document doc = Jsoup.parse(result);
Elements es = doc.select(".b_algo h2 a");
for (Element e : es) {
msg = new Message();
msg.setTitle(e.html());
msg.setUrl(e.attr("href"));
msg.setContent(e.parent().parent().select(".b_caption").html());
list.add(msg);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
小小的总结
坦白的说,目前很多搜索网盘稳定的做法是采用第一种思路,为什么呢?
如果你用的是自定义谷歌搜索技术,设置好了,就很稳定了,但是你要解决怎么让国内用户访问得到的问题。所以有些人的做法是写接口放一套源码在香港,或是国外,主要是可以访问谷歌的就可以了。
然后在国内调用写的接口,在做一个数据展示即可。
那我项目中采用的是必应的搜索引擎,好处就是不用担心国内还是国外都可以访问,缺点就是:使用搜索次数到一定的量的时候,就无法返回数据了。我个人猜测是,必应有一套属于自己的算法,看是否为爬虫或是机器人去调用他们的接口
在实际中,我是遇到过这样的问题,比如刚刚部署好的项目,开始的1-2天搜索什么都可以出来,但是4-5后如果使用的人多了搜索的次数多了,就会出现一个问题,搜索什么都没数据了。
【写在最后】
也说明了一些问题,分享这个源码的初衷就是为了相互学习,喜欢就下载。
当然,如果你也想法,你完全可以下载我的做的更好,可以加一个后台等等。
访问地址:http://localhost:8080/baidu/
猜你喜欢


- /
- /baidu
- /baidu/.classpath
- /baidu/.gitignore
- /baidu/.project
- /baidu/.settings
- /baidu/.settings/.jsdtscope
- /baidu/.settings/org.eclipse.jdt.core.prefs
- /baidu/.settings/org.eclipse.wst.common.component
- /baidu/.settings/org.eclipse.wst.common.project.facet.core.xml
- /baidu/.settings/org.eclipse.wst.jsdt.ui.superType.container
- /baidu/src
- /baidu/src/com
- /baidu/src/com/search
- /baidu/src/com/search/entitys
- /baidu/src/com/search/impl
- /baidu/src/com/search/interfaces
- /baidu/src/com/search/servlet
- /baidu/src/com/search
- /baidu/src/com
- /baidu
 相关代码
最近下载
相关代码
最近下载



 最近浏览
最近浏览
