cuihui123
2020-07-04 11:20:17
原证精
python+vue实现网站爬虫&数据分析案例
项目描述
基础环境:python + flask + vue + element-ui + echarts
python_spiders -- 爬虫后台项目
python_spiders_web -- 爬虫前台项目
运行环境
python 3.8.3 + nginx + mysql
项目技术(必填)
Python 3.8.3 + flask + vue 2.6.11 + element-ui 2.13.1 + echarts + jquery
数据库文件(可选)
链接:https://pan.baidu.com/s/1gaIdr426FczThXDPjio5Ng
提取码:m772
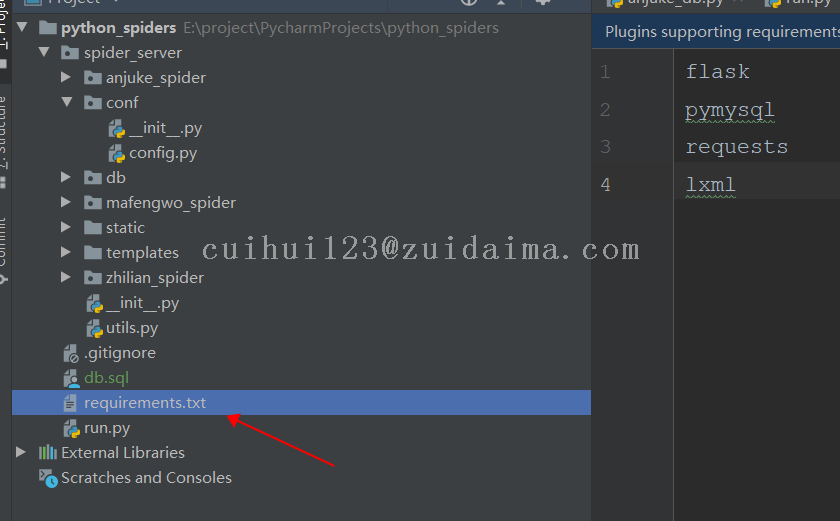
依赖包文件(可选)
见爬虫后台项目requirements.txt
安装命令:
pip3 install xxx
运行视频(可选)
https://www.bilibili.com/video/BV1eX4y1K7P9/
是否原创(转载必填原文地址)
原创
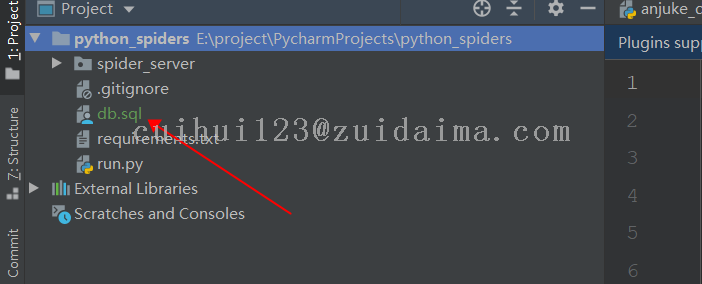
项目截图(必填)
1 爬虫后台项目
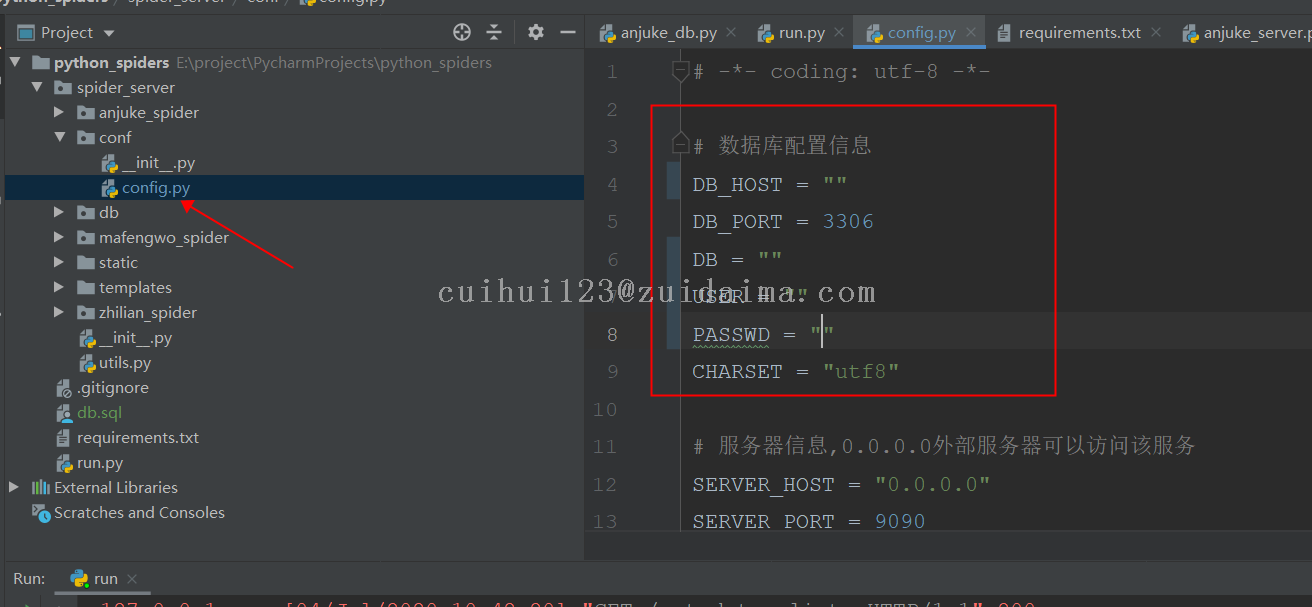
 2 修改数据库配置
2 修改数据库配置
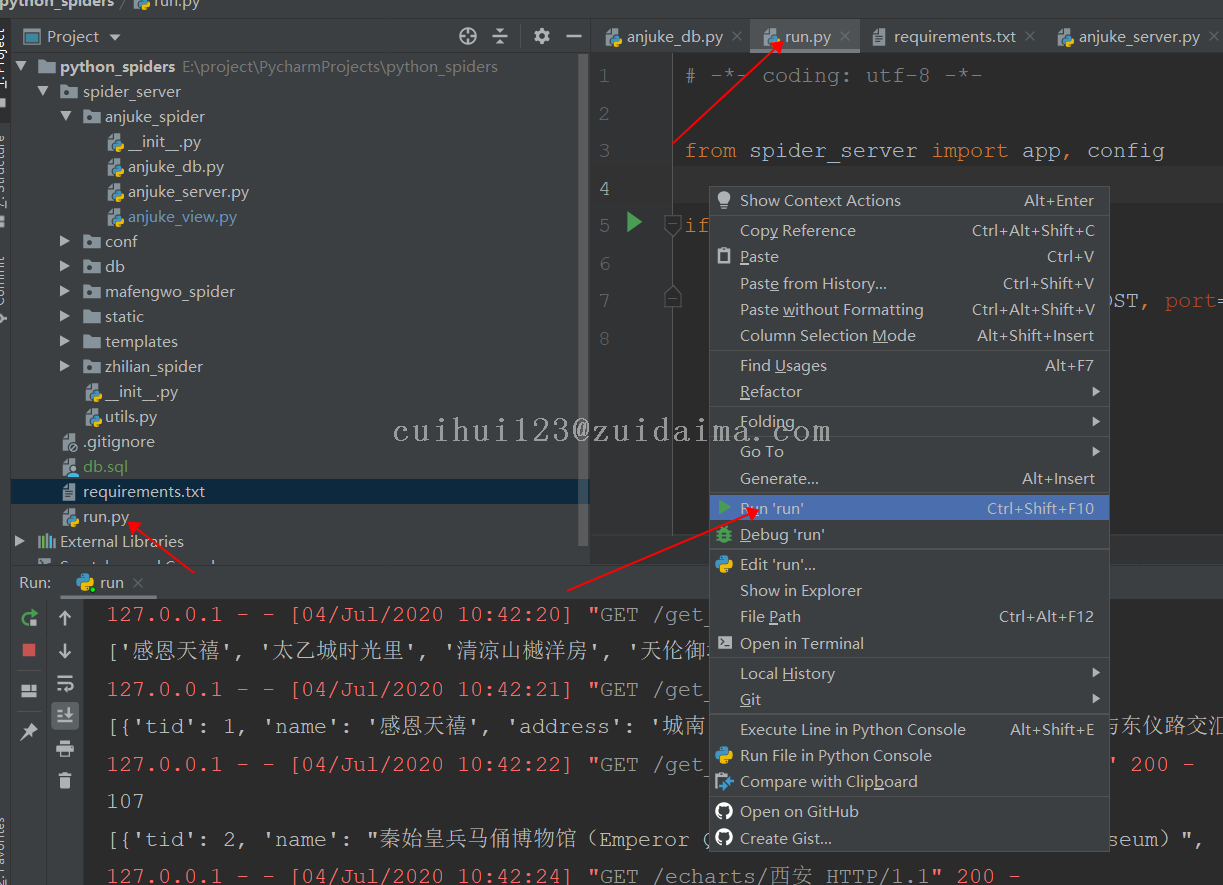
3 启动项目
4 爬虫前台项目

4 前台项目安装模块&运行


运行截图(必填)
1 登录页面,登录未做实现,该项目重点不在登陆,如有兴趣,可参考我的其他项目
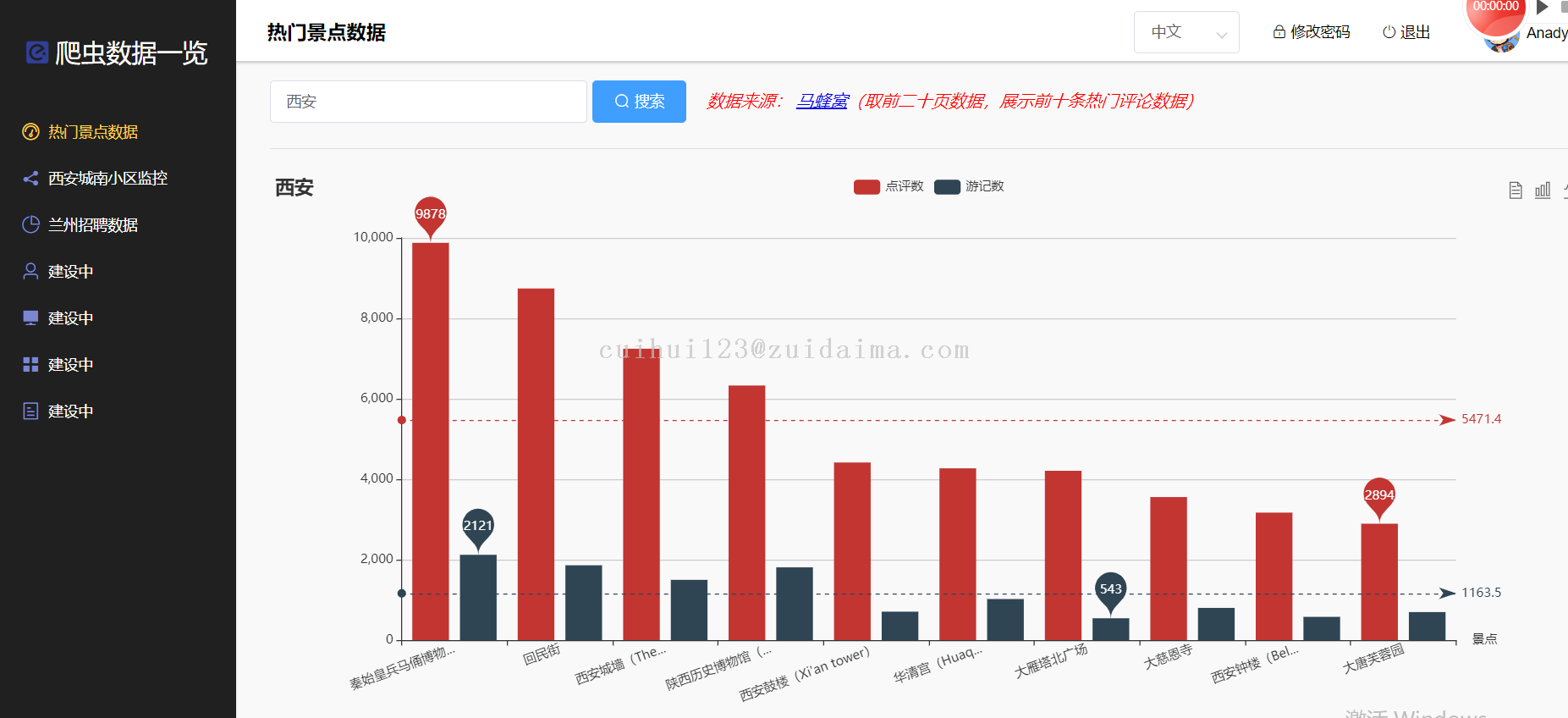
 2 马蜂窝爬虫数据
2 马蜂窝爬虫数据
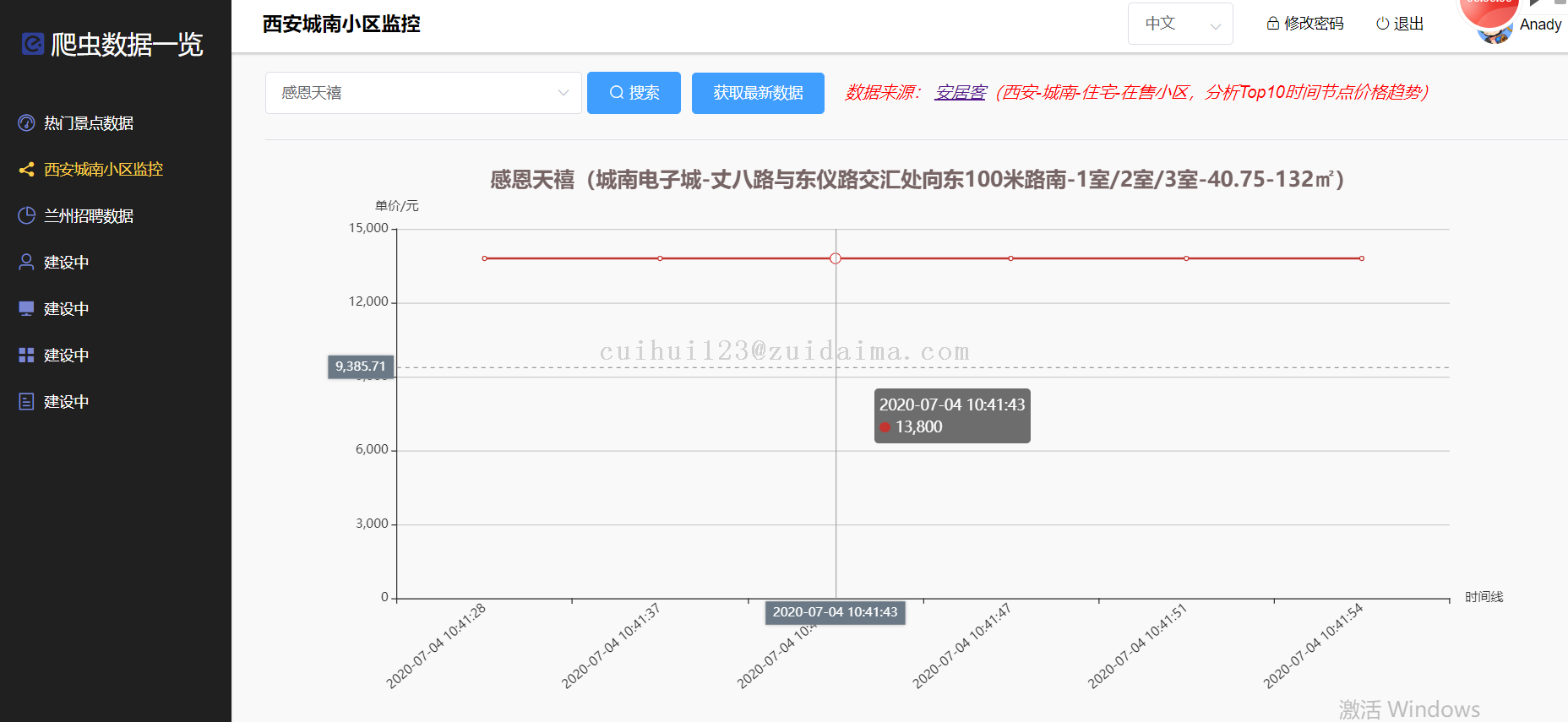
 3 安居客爬虫数据
3 安居客爬虫数据
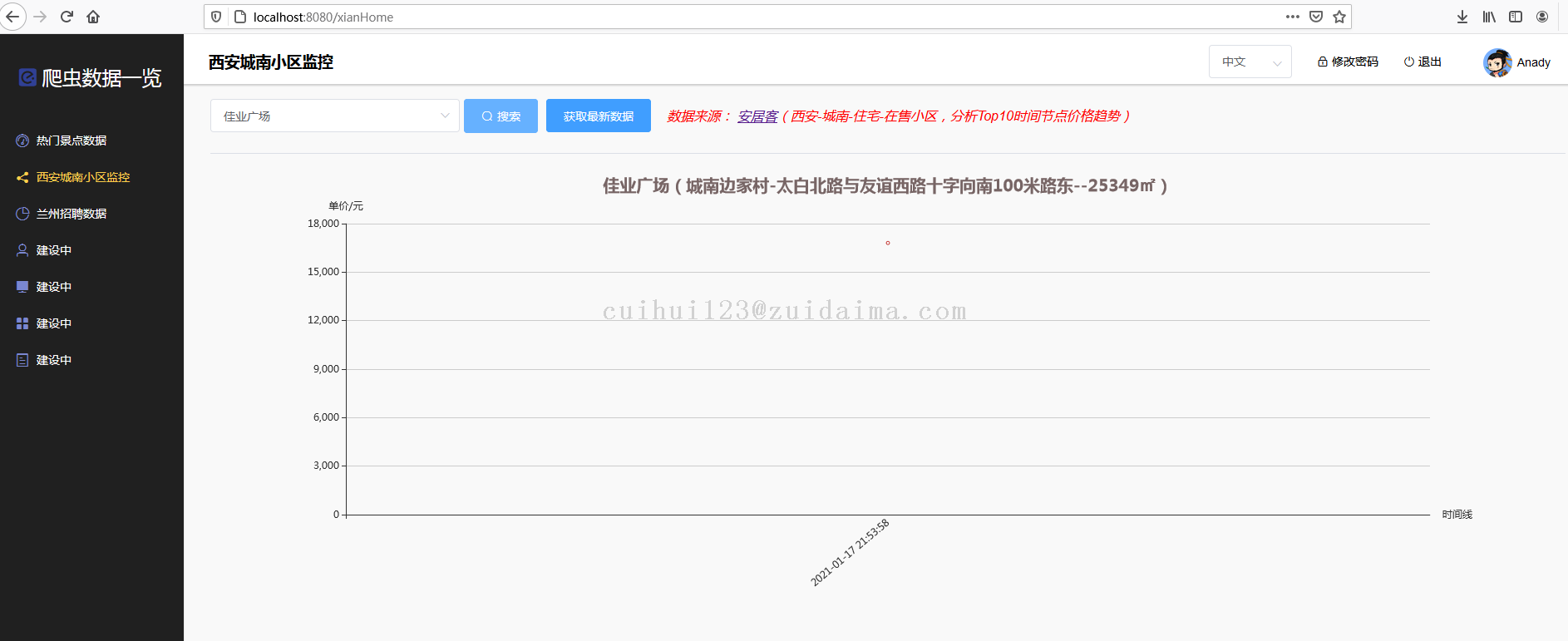

注意事项(可选)
1.python环境安装,npm安装此处不做过多说明
2.由于网站改版,所有xpath的路径需要自行更新
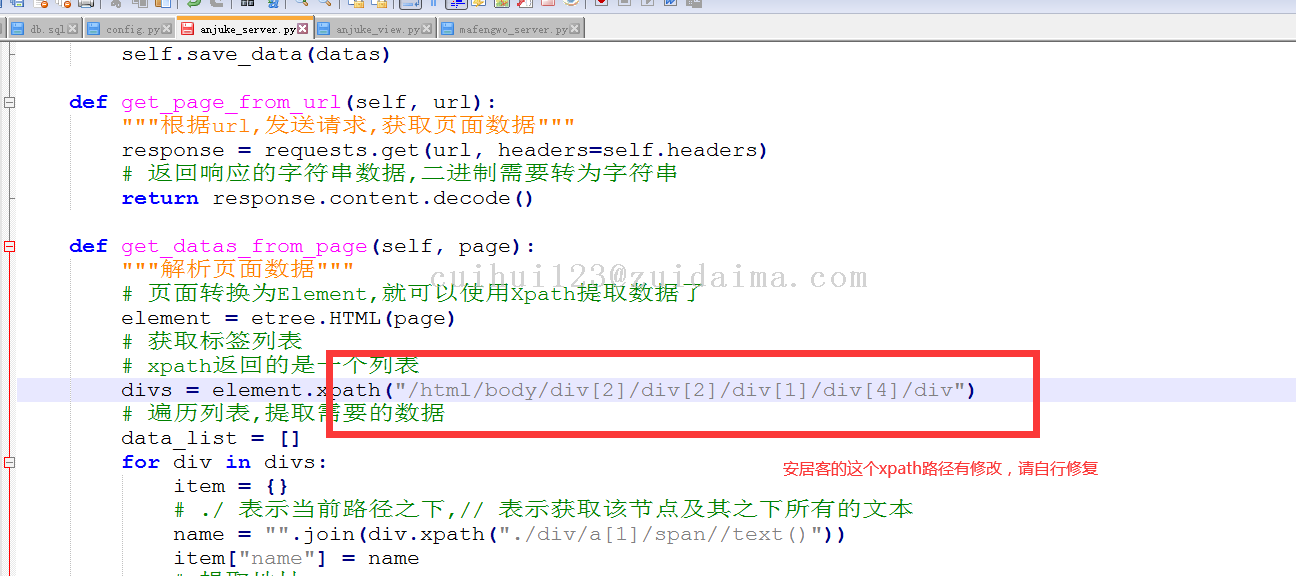
可以通过浏览器实现
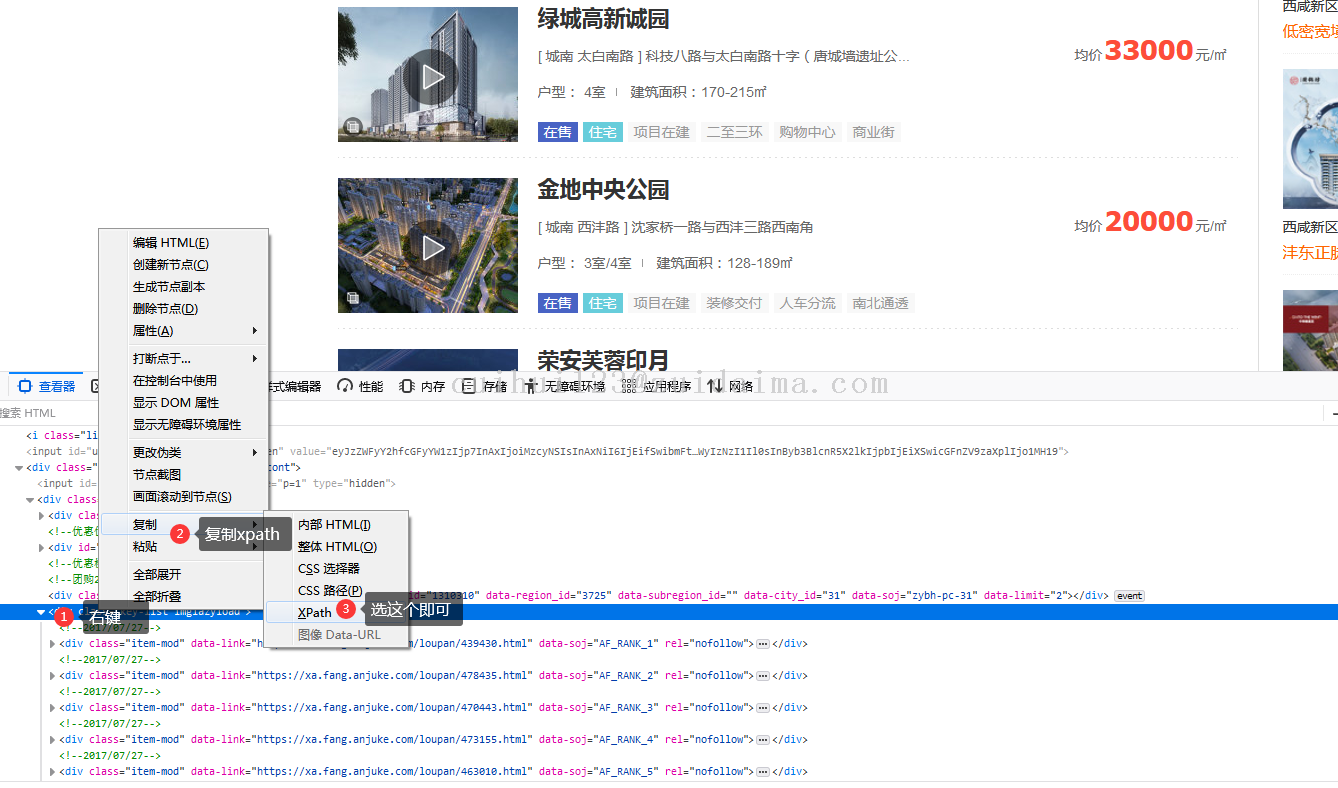
最后得到这个路径
/html/body/div[2]/div[2]/div[1]/div[4]/div
猜你喜欢
- python+selenium爬虫按关键词搜索实现自动化抓取淘宝商品写入mongodb数据库
- python爬取豆瓣电影top250电影数据
- python爬虫抓取并显示新型肺炎数据+分析系统
- 不到200行Python代码爬个小说网站
- python前程无忧数据分析师岗位招聘情况爬取
- python基本数据统计
- python数据分析--农场与社会保障的关联分析
- python爬取前程无忧招聘网站数据及可视化分析
- Python实现抓取豆瓣评分最好的250部电影
- python脚本抓取百度美女图片
- python模拟表单登录www.zuidaima.com网站的脚本分享
- python爬虫练手,爬取网站指定小说全部章节,写入txt文件
已有1人打赏

文件名:爬虫项目源码.zip,文件大小:1438.354K
下载
- /
- /python_spiders_web
- /python_spiders_web/.gitignore
- /python_spiders_web/README.md
- /python_spiders_web/babel.config.js
- /python_spiders_web/package-lock.json
- /python_spiders_web/package.json
- /python_spiders_web/public
- /python_spiders_web/public/index.html
- /python_spiders_web/src
- /python_spiders_web/src/App.vue
- /python_spiders_web
 相关代码
最近下载
相关代码
最近下载

 最近浏览
最近浏览
飞翔的面包片 LV13
3月31日


tony_lee LV6
2024年12月23日
zengpeifang LV6
2024年12月6日
tiancj LV1
2024年11月25日
微信网友_6779541724286976
2024年11月15日
暂无贡献等级
小骆驼 LV3
2024年11月1日
微信网友_7211237575856128
2024年10月23日
暂无贡献等级
Adguard LV3
2024年9月13日
微信网友_7103578196365312
2024年7月31日
暂无贡献等级
Lhh201016
2024年7月25日
暂无贡献等级
