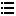 Python爬虫代码实例下载
Python爬虫代码实例下载
小白小怪 LV10
2021年6月19日
项目描述1.提取电影排名、名称、评分、评价人数、推荐语等信息;爬去每部电影的宣传图片分别以电影名命名放到命名为“海报”文件夹里。2.编写函数将第四步提取的信息写入文档;3.编写函数找出所有无推荐语的电影插入命名为’no_desc_movies’中。运行...



socket LV6
2021年1月11日
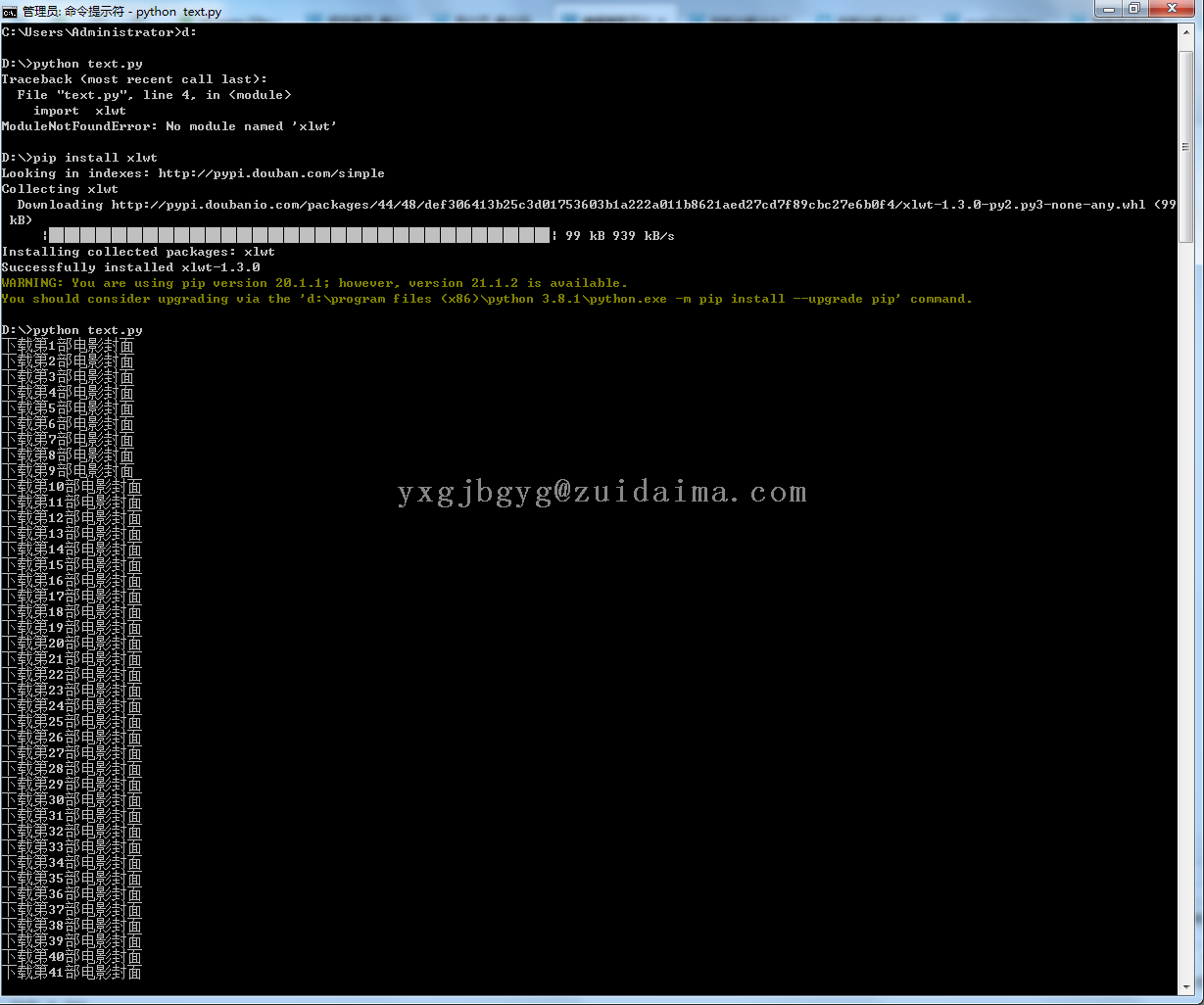
项目描述python爬取包括首页、搜索、分类、详情、章节目录、章节内容运行环境Python3.6+项目技术(必填)python第三方库requests,urllib,lxml依赖包文件pip install requestspip install urllib3pip install lxml是否原...


cuihui123 LV6
2020年7月4日
项目描述基础环境:python + flask + vue + element-ui + echartspython_spiders -- 爬虫后台项目python_spiders_web -- 爬虫前台项目运行环境python 3.8.3 + nginx + mysql项目技术(必填)Python...


随便取个名字_哈哈 LV27
2020年6月14日
项目描述使用selenium、webdriver爬取淘宝的图片、商品、价格等信息。在命令行界面输入爬取的参数,把参数信息记录到txt文件中,运行爬虫程序后,先使用手机扫码登陆,然后pc端网页会自动翻淘宝的网页,知道翻到淘宝的最后一页,就会停止对商品的爬取web端功能:1.下拉框选择商品搜索2.点击图...

liuxuan123 LV1
2020年3月15日
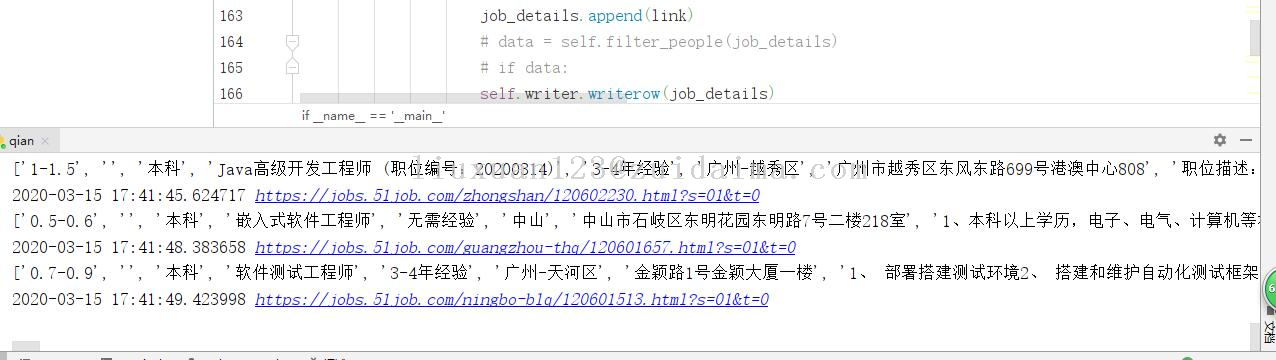
项目描述本项目数据来源于前程无忧,利用爬虫技术爬取前程无忧招聘信息,爬取的信息包括公司名称、职位名称、职位、薪水、工作经验、学历要求、工作地点、公司领域、公司规模;总共爬取了3000多条记录;运行环境python3.8+pycharm项目技术(必填)python爬虫依赖包文件(可选)需要安装如下框架...


interface LV22
2020年2月9日
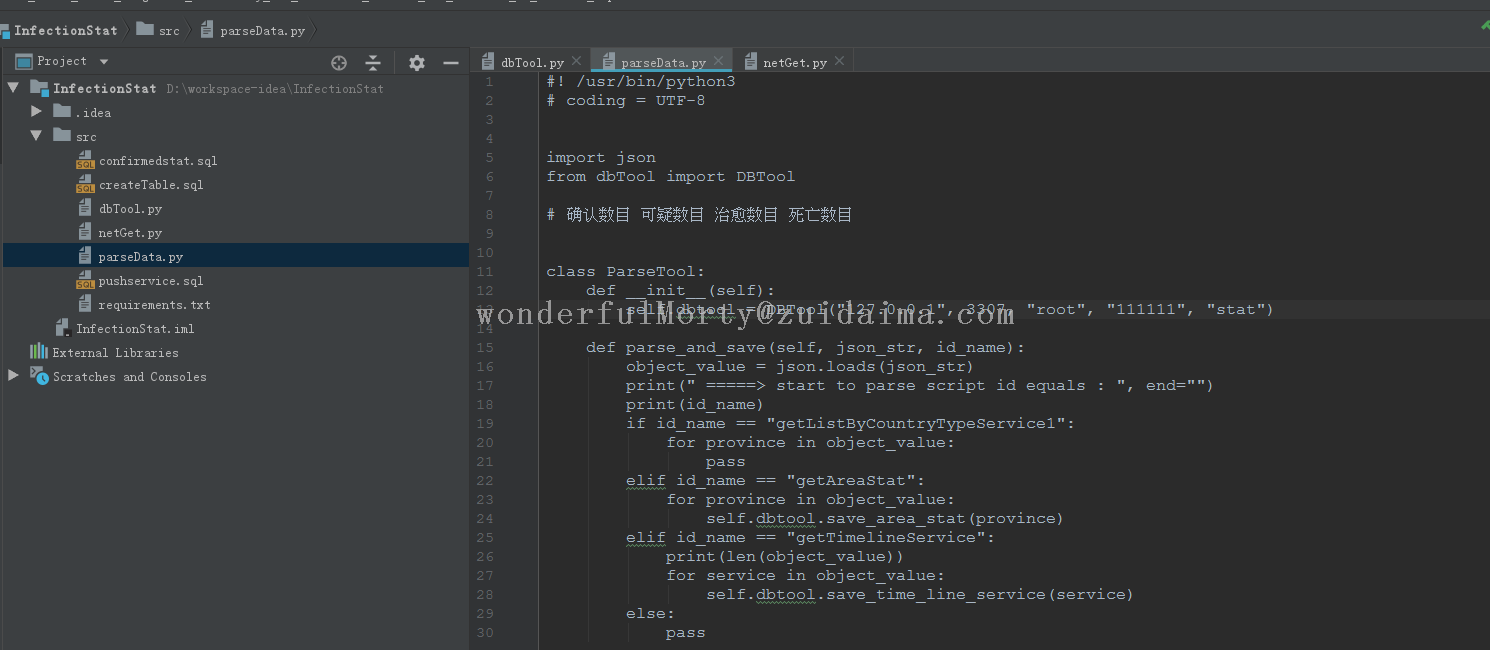
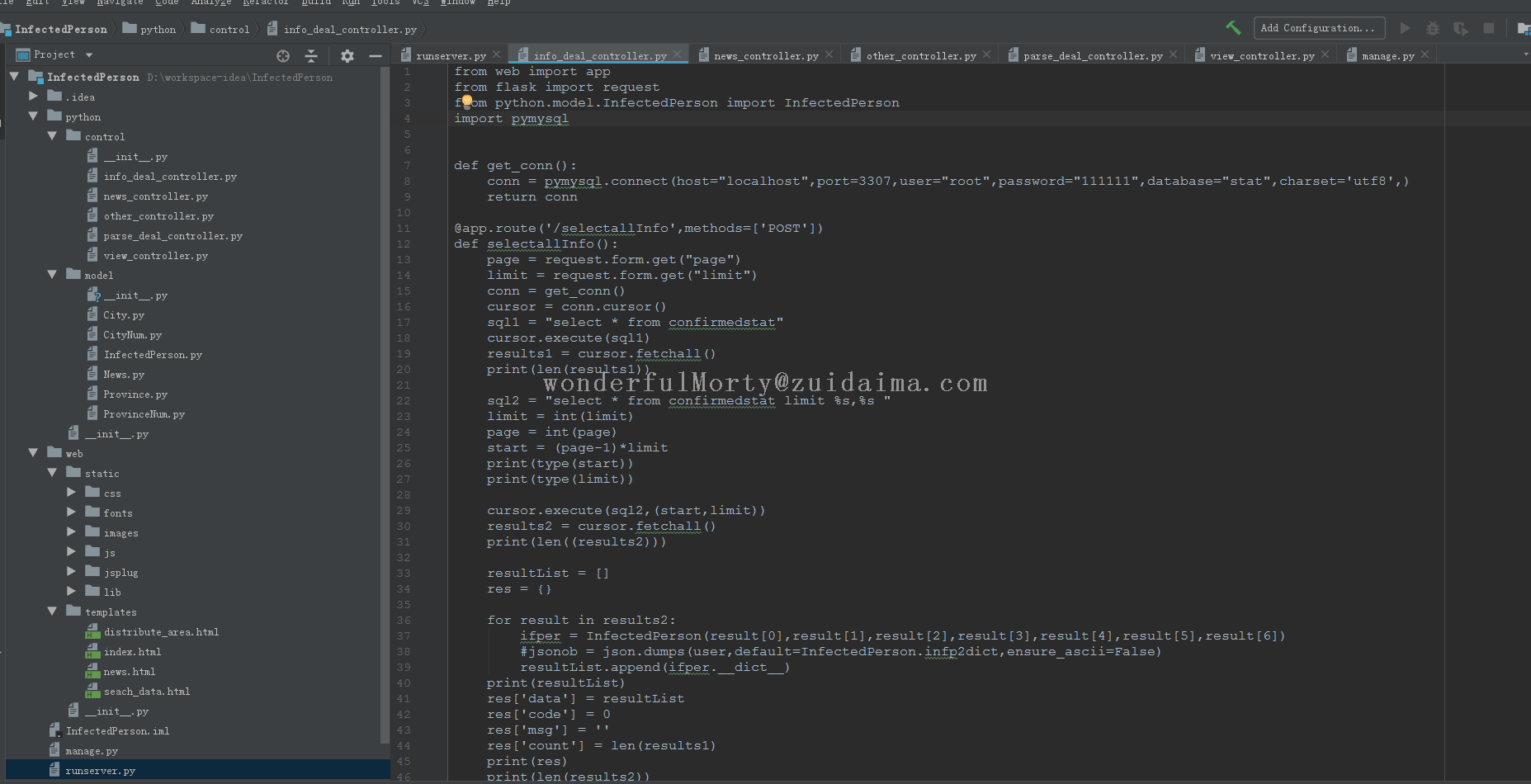
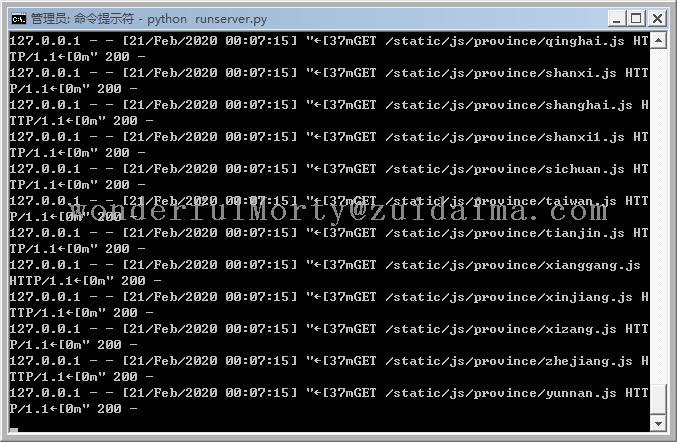
项目描述2020年新冠疫情省市数据可视化地图,根据网上代码做了修改运行环境python 3.x项目技术(必填)python 3.x数据库文件无依赖包文件# pip install fake_useragent# pip install pyecharts# pip install requests运...

yxd1130 LV11
2019年12月20日
项目描述python脚本抓取百度美女图片运行环境python3.7+IntelliJ IDEA项目技术(必填)python基础知识是否原创(转载必填原文地址)是项目截图(必填)运行截图(必填)注意事项需要python环境...

chen491733492 LV6
2019年9月7日
项目描述python多线程高效爬取妹子图片运行环境python项目技术(必填)python3项目截图(必填)运行截图(必填)注意事项默认是下载D盘的,所以需要有D盘...



别让自己无聊 LV13
2019年6月18日
项目描述抓取豆瓣最评分最好的250部电影运行环境ubuntu+Python2.7项目技术(必填)Python数据库文件无jar包文件无是否原创(转载必填原文地址)非原创,项目截图(必填)运行截图(必填)注意事项需要导出在Windows上查看,Linux上编辑处于乱码...



rzaimx LV3
2019年3月2日
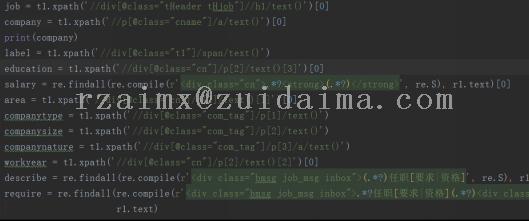
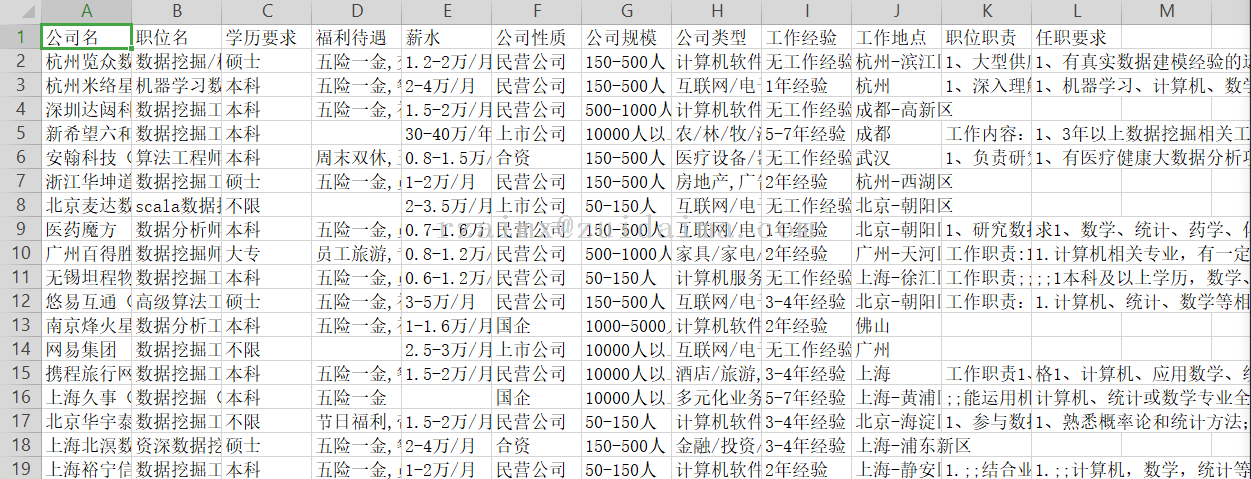
{代码...}项目描述从前程无忧招聘网站上进行网页抓取,提取各项数据,数据包含多个维度,分别是城市、岗位名称、公司名字、公司规模、公司类型、经验要求、学历要求、专业要求、福利待遇和所属行业等。对爬取的数据进行数据清洗及标准化后,实现数据分析和可视化。最后实践apriori算法,进行频繁项集提取及关联分析。运行环境...

hegang3 LV6
2018年12月18日
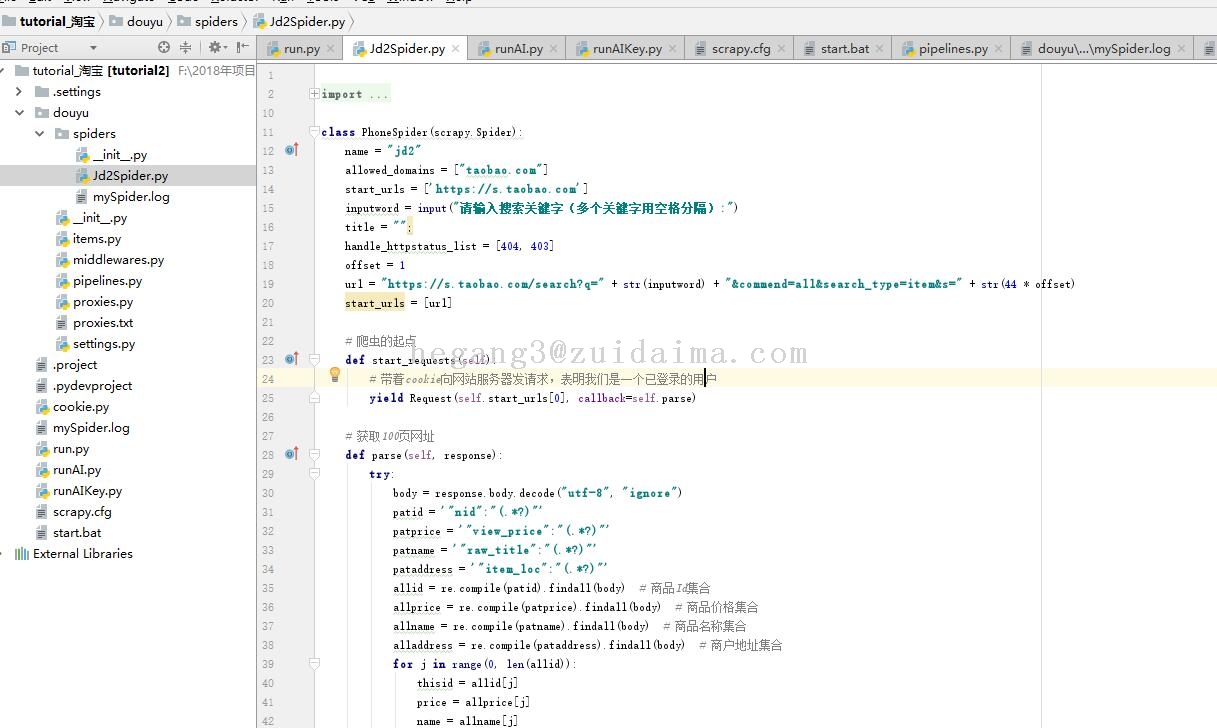
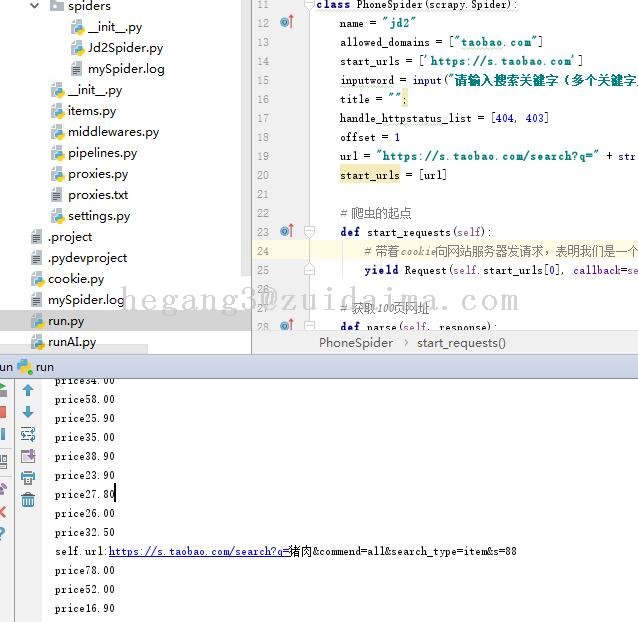
项目描述运用python语言编写,使用scrapy框架。专业数据爬取框架Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。运行环境pycharm python 项目技术(必填)python&nbs...

lgj123 LV9
2018年11月30日
项目描述python实现猫TV网站小爬虫运行环境python 3.0以上项目技术(必填)python数据库文件无jar包文件无是否原创(转载必填原文地址)转载项目截图(必填)运行截图(必填)注意事项无...

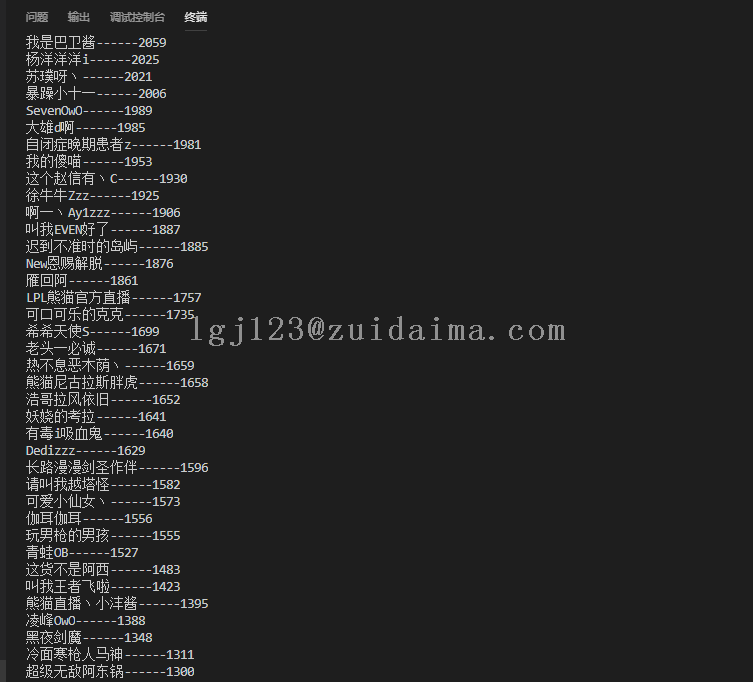
sys0613 LV12
2018年7月26日
项目描述初学python,练习爬取小说网站,指定小说全部章节运行环境win7+python3.5(安装requests、BeautifulSoup组件)+任意文本编辑工具项目技术(必填)python3+少量html知识数据库文件无jar包文件无是否原创(转载必填原文地址)原创项目截图(必填)仅10几...
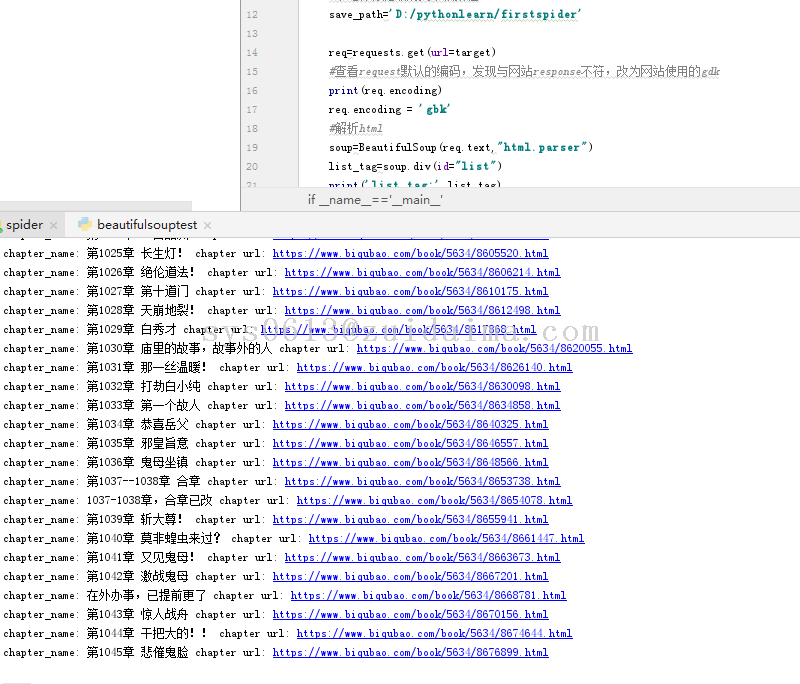
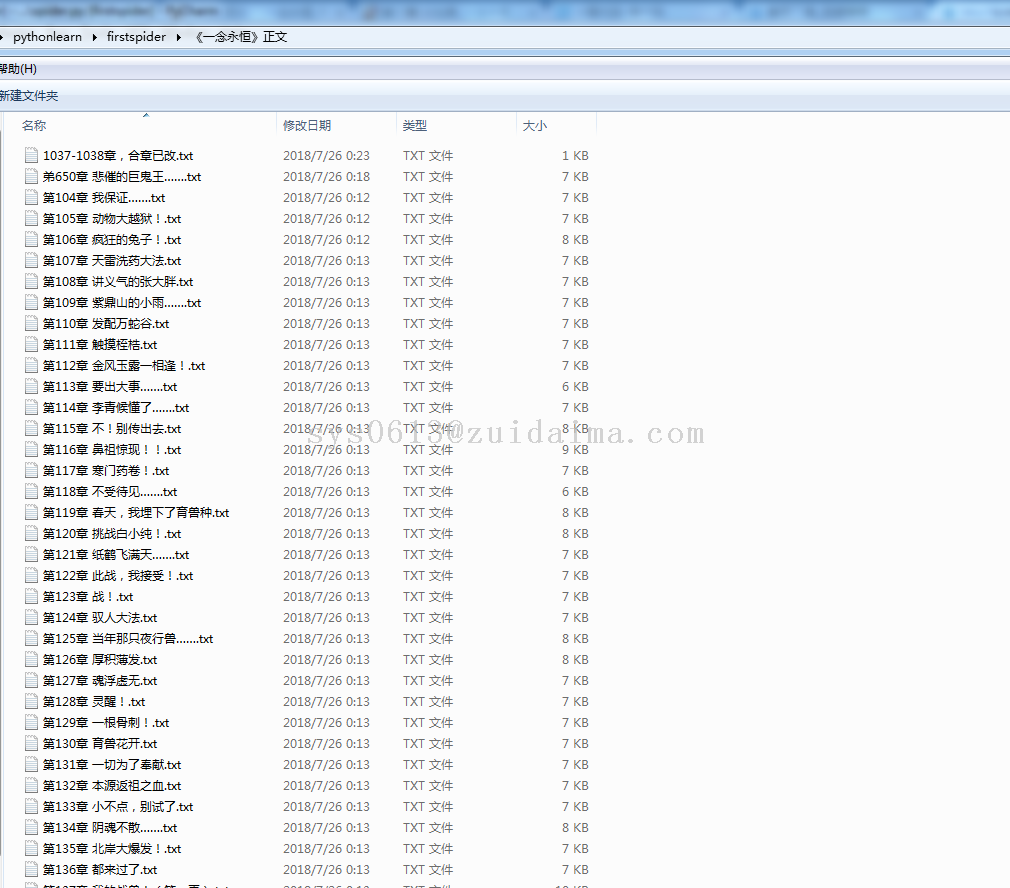


allen平凡之路 LV12
2017年11月30日
闲着没事。想找点壁纸,于是用python写个爬虫来爬个壁纸吧。(需要在D盘根目录创建images文件夹) ...
何果财 LV3
2014年11月12日
分享的是一段较简单的爬虫,采用的网页分析方法是HTMLparser,抓取某个特定标签下的内容并存入excel表中。...
